
From the conversion glossary
Concepts referenced in this article, defined.
Learn how to validate A/B test results before scaling using the right metrics, segmentation, and CRO best practices with CustomFit.ai.
Concepts referenced in this article, defined.
Run rigorous A/B tests and personalize every visit on Shopify or any storefront — no engineers required.
You finally see it in your dashboard.
Variant B is outperforming Variant A. The conversion rate is up. Revenue looks higher. Someone on the team says, “This is a winner. Let’s roll it out everywhere.”
This moment feels good. After weeks of planning, building, and waiting, it feels like proof that the work paid off.
But here is the uncomfortable truth many ecommerce and D2C brands learn the hard way.
Not every A/B test winner is a real winner.
Some “winning” tests quietly fail after rollout. Some perform well for a short window and then regress. Others lift one metric while hurting another that matters more. And some wins are simply statistical noise that looked convincing because traffic spiked or behavior shifted temporarily.
Before you scale any A/B test across your ecommerce store, especially during high-traffic periods or campaigns, you need to slow down and double-check what you are seeing.
This guide walks through how to validate whether your A/B test is truly a winner before scaling. We will cover behavioral signals, statistical checks, segmentation traps, and practical validation steps. We will also touch on how teams using an A/B Testing Platform like CustomFit.ai approach this process in a structured way without turning it into overanalysis.
This is not about doubting experimentation. It is about respecting it.
A/B Testing is powerful, but it is also easy to misinterpret.
Most ecommerce teams run tests under real-world conditions. Traffic is uneven. Campaigns start and stop. Discounts overlap. Behavior shifts by device, region, and time of day.
In this environment, it is surprisingly easy for a test to appear successful without being truly reliable.
Here are a few reasons false winners show up so often.
When teams rush to scale without validating these factors, they often end up rolling out changes that do not actually increase conversion rate over time.
The first question to ask is deceptively simple.
What exactly did this test optimize for?
Many A/B tests are set up around convenient metrics instead of meaningful ones. For example:
These metrics are not useless, but they are often proxies. During the holidays or high-intent periods, proxies can mislead.
Before scaling, ask:
Did this test improve the metric that actually drives revenue?
For an ecommerce store, the most reliable primary metrics usually include:
If your test “won” on clicks but did not move add to cart or checkout completion, you need to pause. That does not automatically make it a bad test, but it does mean it is not ready to be scaled globally.
Teams using a structured A/B Testing Platform typically define a single primary metric upfront and treat other metrics as secondary signals. This clarity makes post-test validation much easier.
One of the most common traps in AB testing is early excitement.
You launch a test. After a few days, Variant B looks clearly ahead. The numbers feel convincing. But early results are often unstable.
Behavior changes throughout the week. Weekends behave differently than weekdays. Campaign launches can temporarily inflate intent.
Before calling a test a winner, review performance across time slices.
A true winner usually shows steady improvement rather than sharp peaks.
This is especially important for ecommerce brands running paid traffic. A short-term surge from ads can make a variant look stronger than it really is.
If you are using a platform like CustomFit.ai, reviewing performance trends over time rather than a single aggregate number helps avoid scaling on shaky ground.
Statistics matter, but they should guide decisions, not paralyze them.
Many teams either ignore statistical confidence entirely or get stuck chasing perfect significance that never arrives.
The practical approach sits in the middle.
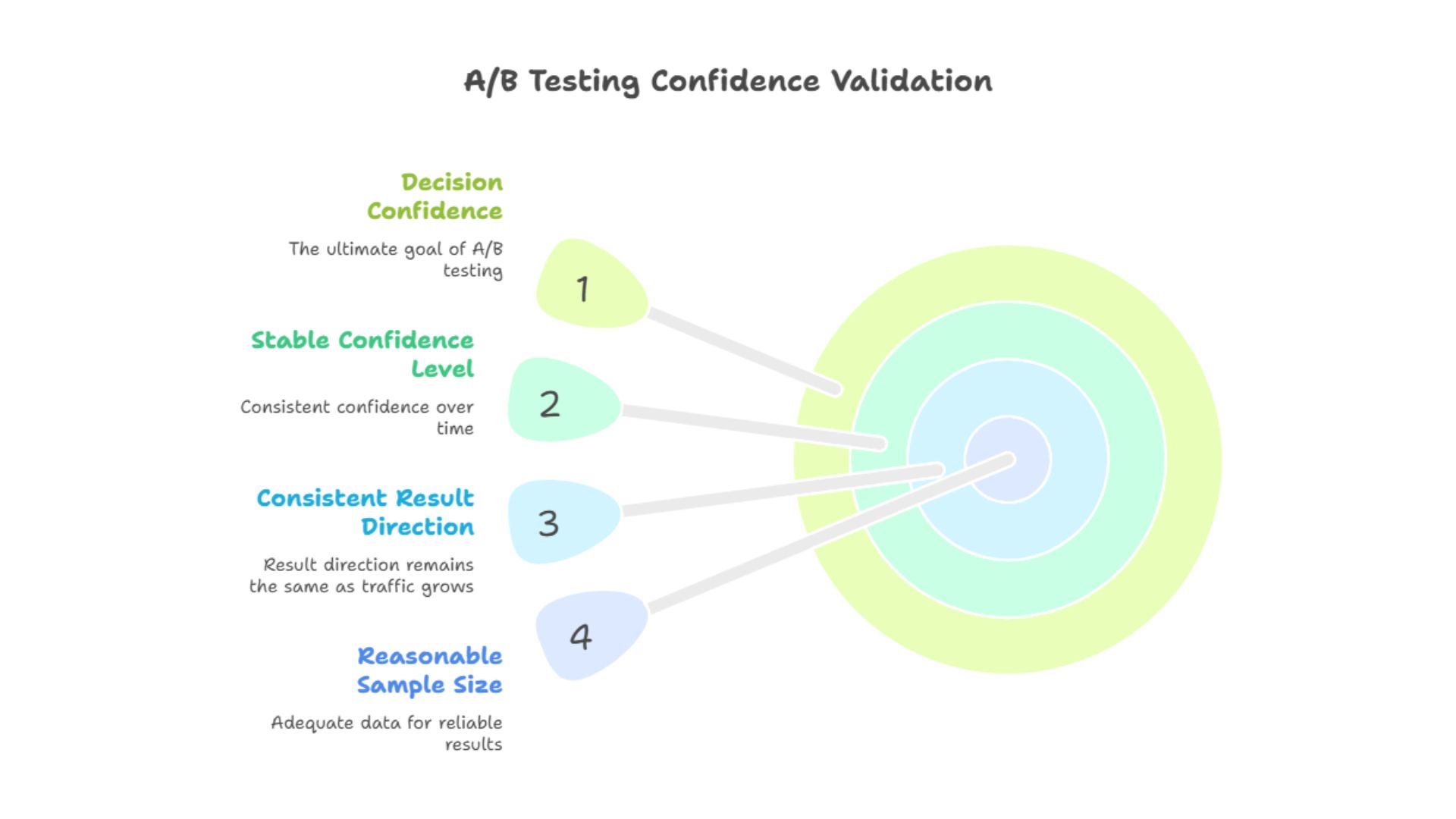
Before scaling, check:
If confidence jumps from 70 percent to 95 percent and back again, the test may not be stable. If it steadily improves as data accumulates, that is a healthier signal.
Modern A/B Testing Platforms simplify this by presenting confidence in a readable way rather than raw statistical jargon. The goal is not academic precision. The goal is decision confidence.
One of the biggest reasons tests fail after scaling is that they only worked for part of the audience.
This is extremely common in ecommerce.
For example:
When you roll out globally without checking segmentation, you flatten these differences and lose the benefit.
Before scaling, break down results by:
If Variant B is a clear winner for a specific segment but neutral or negative for others, the right move may not be full rollout. The smarter move may be personalization.
This is where tools like CustomFit.ai become especially useful, because they allow teams to turn a segment-specific win into a targeted experience instead of forcing it on everyone.
A/B tests rarely affect only one part of the funnel.
A change that increases add to cart might reduce checkout completion. A design that feels urgent might increase purchases but also increase returns or cancellations.
Before scaling, review downstream metrics carefully.
Ask:
These effects often show up quietly. If you scale too fast, you may only notice weeks later when revenue quality drops.
A responsible A/B Testing process treats conversion rate as part of a system, not an isolated number.
Some changes are low risk. Others are not.
If your test affects:
It is worth validating twice.
This does not mean starting from scratch every time. Sometimes extending the test for another cycle or rerunning it during a different traffic mix is enough.
For example:
If the result repeats, confidence increases dramatically.
Conversion rate optimization companies often encourage this discipline because it prevents high-impact mistakes that are expensive to reverse.
Data is powerful, but logic still matters.
Before scaling, ask a simple question.
Does this result make sense given how users behave?
If a tiny copy change produced a massive lift, be cautious. If removing important information somehow increased conversion dramatically, dig deeper.
True winners usually align with behavioral intuition:
If the result feels too good to be true, it often is.
This does not mean dismissing surprising wins. It means understanding them before acting.
Scaling does not have to be all or nothing.
Instead of instantly rolling out to 100 percent of traffic, consider phased scaling.
A good A/B Testing Platform makes it easy to control exposure and rollback if needed.
This approach reduces risk while still capturing upside.
Before moving on, it is worth calling out a few recurring mistakes.
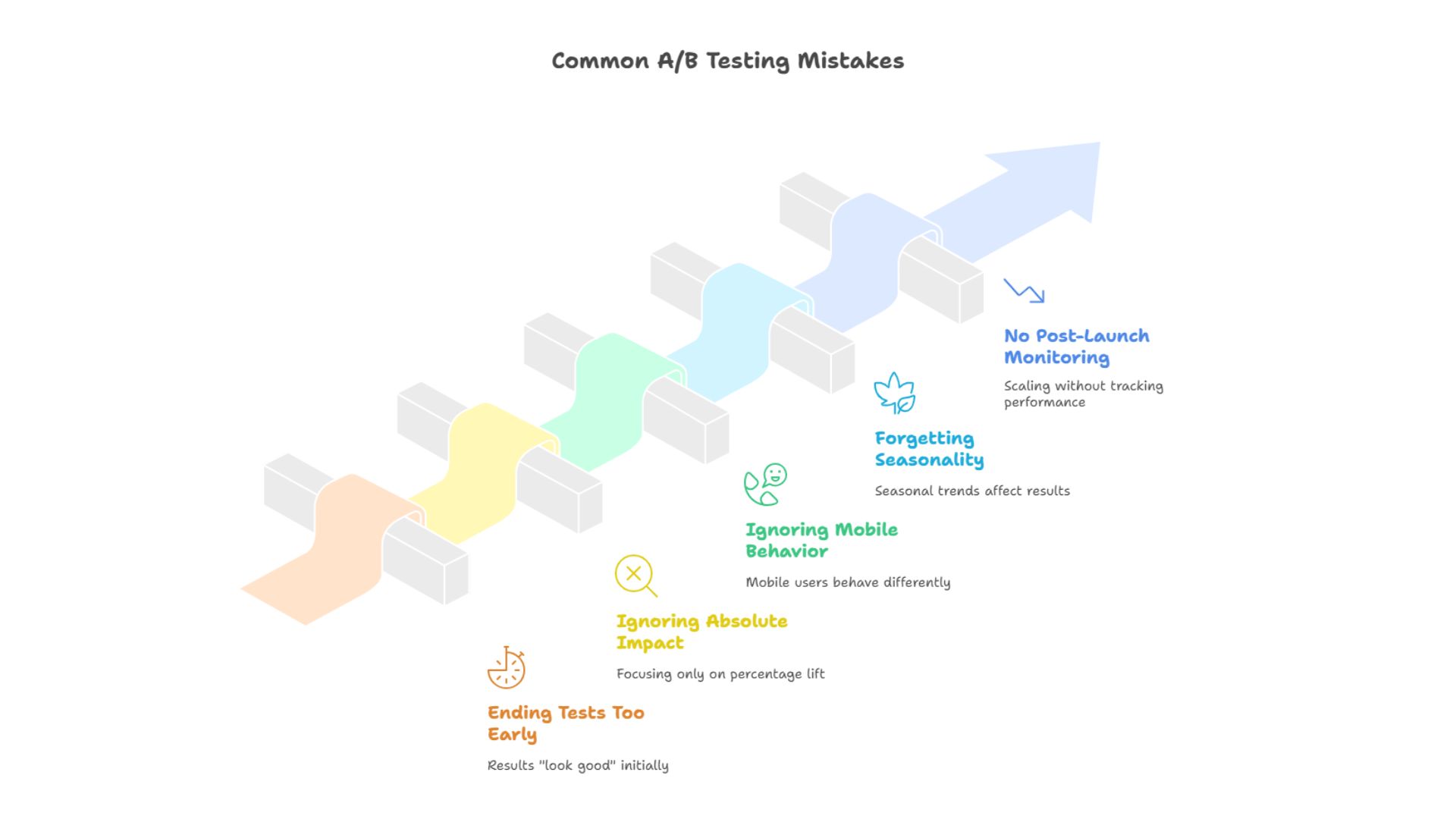
Avoiding these mistakes does not require advanced math. It requires patience and structure.
CustomFit.ai is a conversion rate optimization company that helps ecommerce teams test, validate, and personalize website experiences without heavy development work.
While the platform simplifies running A/B tests, its real value shows up after the test ends.
Teams can:
This makes scaling safer and more intentional, especially for D2C brands operating under high traffic pressure.
The tool does not decide for you. It gives you the clarity to decide well.
The goal of A/B Testing is not to chase wins. It is to build confidence in decisions.
When teams validate properly before scaling, they:
Over time, this discipline compounds. The ecommerce store becomes more stable, more predictable, and more resilient under pressure.
A test that survives validation is far more valuable than a test that simply “won” once.
Seeing a positive A/B test result is exciting. Scaling it responsibly is where the real work begins.
Before you roll out any test widely, pause and ask:
If the answer is yes across these questions, you are likely looking at a true winner.
A/B Testing is not just about finding changes that work. It is about finding changes that keep working.
That is how you turn experiments into sustainable growth.
A real A/B test winner is one that consistently improves a meaningful business metric such as conversion rate or revenue, holds up across time and segments, and does not harm other parts of the funnel after scaling.
Many tests appear to win due to short-term behavior, campaign effects, or specific segments. When rolled out globally, those conditions disappear, and performance drops.
There is no fixed duration, but tests should run long enough to capture different traffic patterns such as weekdays and weekends. Stability over time matters more than speed.
Statistical confidence is important, but it is not enough on its own. Teams should also review segment performance, downstream metrics, and behavioral logic before scaling.
Segment analysis reveals whether a test worked broadly or only for certain users. This insight helps decide whether to roll out globally or use personalization instead.
Yes. Poorly validated changes can harm engagement metrics that indirectly affect SEO. Responsible AB Testing for SEO focuses on improving clarity and user experience, not just short-term clicks.
Focus on conversion rate, checkout completion, revenue per visitor, and any downstream signals such as refunds or cancellations.
For high-impact changes, rerunning or extending tests can confirm reliability and reduce risk. This is especially important for pricing, checkout, or navigation changes.
A good A/B Testing Platform provides clear reporting, segment breakdowns, controlled rollouts, and post-launch monitoring so teams can validate results before scaling.
CustomFit.ai helps ecommerce teams analyze test performance deeply, personalize winning experiences for specific segments, and roll out changes gradually while monitoring impact. This reduces risk and improves long-term conversion rate outcomes.