
From the conversion glossary
Concepts referenced in this article, defined.
Concepts referenced in this article, defined.
Run rigorous A/B tests and personalize every visit on Shopify or any storefront — no engineers required.
A/B testing automation eliminates the manual overhead of test management — traffic allocation, monitoring, winner detection, result reporting, and variant rollout — so your team spends time on hypothesis generation and interpretation rather than administration. The goal is a testing program that runs faster and at higher volume with the same (or smaller) team. Automate the mechanics; keep human judgment for decisions that matter.
Most D2C teams that want to test more are slowed down by mechanics, not strategy. The common bottlenecks:
Manual setup: Every test requires clicking through configuration settings, setting up goals, defining traffic splits, and scheduling start/end dates. Multiplied across 20+ tests per quarter, this is significant overhead.
Manual monitoring: Someone has to check whether tests have reached significance, catch tests that break (JavaScript errors, tracking failures), and notice when traffic volumes have shifted significantly.
Manual winner selection: After a test reaches significance, someone has to review results, make the rollout decision, implement the winning variant in the live store, and clean up the test setup.
Manual reporting: Generating reports on test results, communicating wins to the broader team, and updating the experimentation backlog all take time.
Automation addresses each of these bottlenecks.
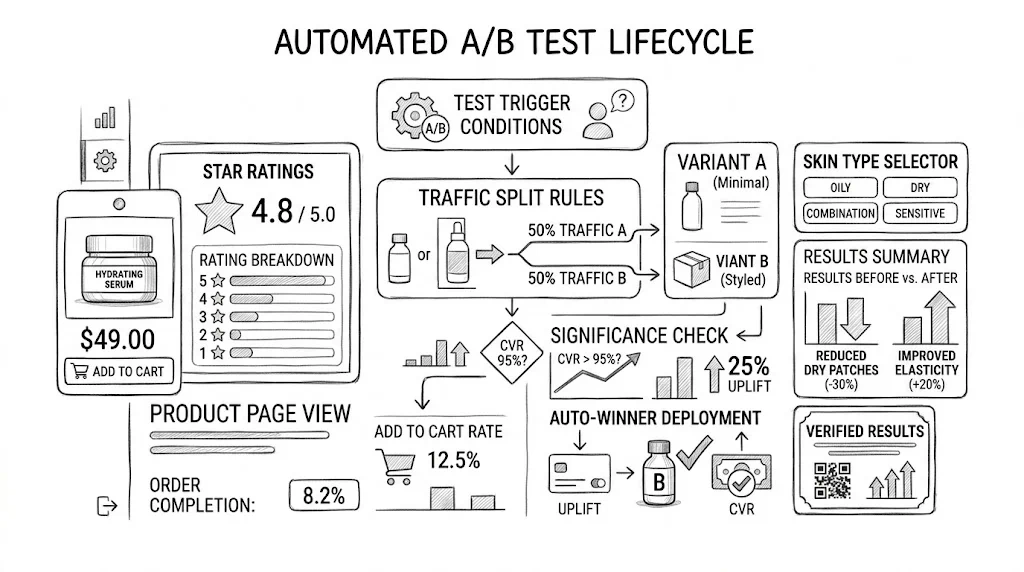
What it is: Automatically route the right percentage of visitors to each variant without manual reconfiguration.
Advanced version — multi-armed bandit: Instead of a fixed 50/50 split, multi-armed bandit algorithms dynamically allocate more traffic to better-performing variants in real time. This reduces the cost of running a losing variant — instead of showing a worse experience to 50% of visitors for 4 weeks, the algorithm progressively reduces traffic to the losing variant.
When to use: Bandit-style allocation is valuable when the cost of running a losing variant is high (e.g., festive campaign landing pages with significant paid traffic). For hypothesis-validation tests where you want clean 50/50 data, stick with fixed splits.
CustomFit.ai support: CustomFit.ai handles traffic allocation automatically, with configurable split percentages and the ability to adjust allocation mid-test without invalidating results.
What it is: Configure tests to automatically end after reaching a target sample size, a target significance level, or a maximum duration — whichever comes first.
Why it matters: Tests that run indefinitely after reaching significance waste traffic and create risk (teams forget to end tests; variants run past their relevance window; seasonal changes make old test results misleading).
Best practice: Set a maximum test duration (e.g., 30 days) and a significance target (e.g., 95% confidence). The test ends when it hits either condition. Add an alert if neither condition is met after 30 days — you need to decide whether to extend or abandon the test.
What it is: Your testing platform monitors significance in real time and sends notifications (email, Slack) when a test reaches your pre-configured threshold.
Why it matters: Without alerts, tests sit at significance for days or weeks before anyone acts. During that time, you're running a test that's already answerable — wasting traffic and time.
Implementation: Configure notification thresholds in your testing tool. CustomFit.ai supports email notifications. For Slack integration, most tools connect via Zapier or native webhook.
What it is: When a test reaches significance, automatically begin routing 100% of traffic to the winning variant — without requiring a developer to implement the change in the production codebase.
Two approaches:
For most Shopify D2C brands using CustomFit.ai, tool-side rollout is fine — the performance overhead is minimal and it's much faster than waiting for a developer to implement every winning change.
What it is: Automated reports that summarize test results, winners, losers, and learning insights — delivered to stakeholders on a schedule.
What to include in automated reports:
Tools: CustomFit.ai's dashboard provides on-demand reporting. For automated email reports, Zapier can connect test completion events to email templates or Notion/Google Sheets documentation.
The most important question in A/B testing — "what should we test next?" — requires human judgment. Hypothesis generation draws on:
AI-powered hypothesis generation tools exist (and are improving) but still produce generic hypotheses that lack the contextual specificity of good human-generated ideas.
How a test is structured — what the variant changes, what's kept constant, how variants are implemented, what the primary metric is — requires careful human thought. Automated test design tends toward cosmetic changes that are easy to implement but low in potential impact.
Statistical significance is a mechanical output. Business judgment is not. A test that shows a 12% CVR improvement may still not warrant rollout if:
A human must interpret results in business context. Automation can surface the data; only a human can decide what to do with it.
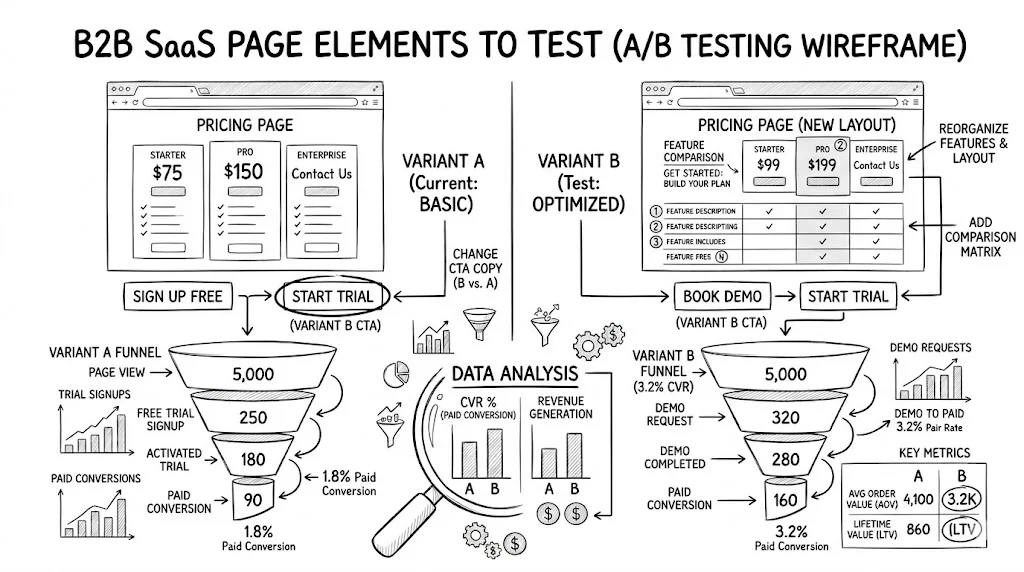
For a Shopify D2C brand using CustomFit.ai, a practical automated testing workflow:
1. Backlog management (manual): Monthly review of test ideas, prioritized by potential impact and ease of implementation. Document each hypothesis, expected outcome, and primary metric.
2. Test setup (partially automated): Configure test in CustomFit.ai using templates from previous similar tests. Set automated end date (30 days maximum) and significance alert threshold.
3. Monitoring (automated): CustomFit.ai monitors significance. Alert fires when threshold reached. No daily check-in required.
4. Decision (manual): Review alert, check segment analysis, assess business context, make rollout decision.
5. Rollout (automated): One-click rollout to 100% traffic in CustomFit.ai. Document result in experiment log.
6. Reporting (partially automated): Monthly automated report generated from experiment log. Reviewed in team meeting.
This workflow allows a one-person growth team to run 4–8 concurrent tests per month without A/B testing becoming a full-time job.
Don't automate the decision to implement winners. Auto-winning features can implement changes automatically when significance is reached — but this removes human judgment from the process. Always have a human review segment data and business context before implementing. Configure auto-rollout only if you've reviewed the segment analysis and established clear rollout criteria in advance.
Automate documentation as well as testing. Most teams are good at automating test mechanics but forget to automate learning capture. Set up an automated workflow that creates a new row in your experiment log whenever a test completes, pre-filling the test name, dates, and result. Humans fill in interpretation.
Review automation settings quarterly. Automation configurations drift — significance thresholds that made sense when you had 500 visitors/day may be wrong at 5,000/day. Review and adjust your automation settings with each major traffic change.
Build in a manual review gate before implementation. Even with high automation, require human sign-off before any test result is implemented. One bad rollout from an auto-implemented test can cost more than months of automation time savings.