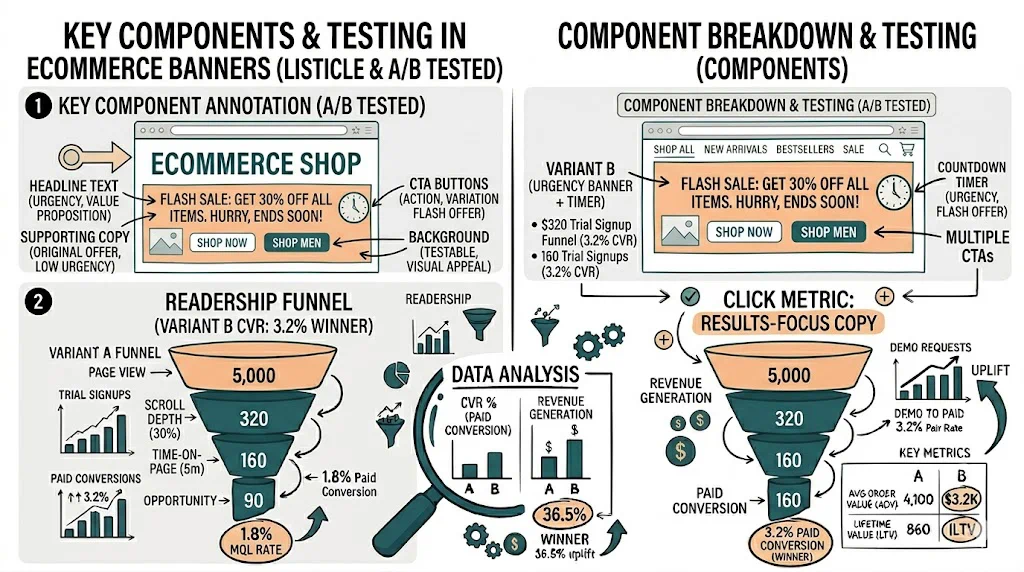
Your A/B testing confidence level determines how certain you need to be before declaring a winner — it directly controls the trade-off between shipping false positives and missing real improvements. A 95% confidence level means you accept a 5% chance of a false positive; 99% cuts that to 1% but requires larger sample sizes; 90% is faster but riskier. For D2C ecommerce brands on Shopify, choosing the right threshold depends on your traffic volume, the stakes of the decision, and how expensive a wrong call would be.
What Confidence Level Actually Means
Confidence level is 1 - α, where α is your significance threshold (the Type I error rate). At 95% confidence:
- α = 0.05 (5% false positive rate)
- You need a p-value < 0.05 to declare significance
- If there is truly no difference between variants, you'll still declare a winner 1 in 20 tests
The confidence level does not tell you the probability that variant B is better. That requires Bayesian reasoning (see Bayesian vs Frequentist A/B Testing). The confidence interval tells you the range within which the true effect plausibly lies, not the probability the variant wins.
The Confidence Level vs Confidence Interval Confusion
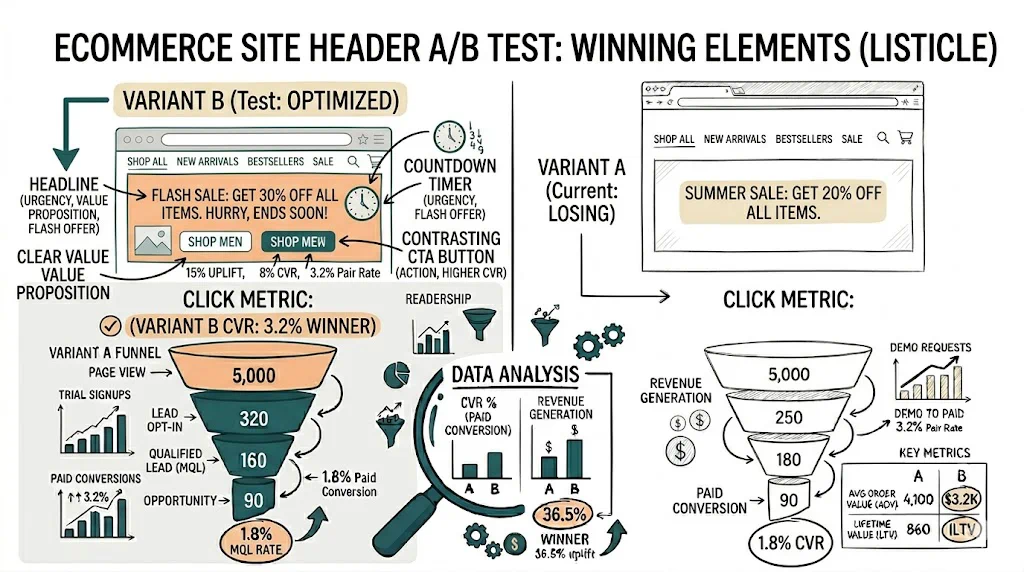
These are related but different:
- Confidence level — the threshold you set (90%, 95%, 99%)
- Confidence interval — the range your test produces (e.g., "lift is between +1.2% and +4.8%")
A 95% confidence interval means: if you repeated the experiment many times, 95% of such intervals would contain the true value. It does not mean "I am 95% certain the lift is between 1.2% and 4.8%."
See the conversion glossary on confidence intervals for a deeper treatment.
90% Confidence Level: When to Use It
What it means: You accept a 10% false positive rate. 1 in 10 "winners" may have no real effect.
Required sample size: ~21% smaller than at 95% confidence (all else equal). This means faster tests.
When to use 90%:
- Very low traffic stores — if you're getting 2,000 visitors/month, waiting for 95% confidence may take 3-4 months. At 90%, you can decide in 6-8 weeks
- Low-stakes tests — headline copy on a blog post, button color changes on secondary pages
- Exploratory testing — when you're trying to quickly eliminate bad ideas, not confirm good ones
- Iterative sprints — if you run 20 tests/year and ship only the top 5, a higher false positive rate at the screening stage is acceptable
Indian D2C context: A bootstrapped Ayurvedic brand with 3,000 monthly visitors testing two product description formats might reasonably use 90%. The cost of shipping the wrong variant is low; the cost of never learning is high.
95% Confidence Level: The Standard
What it means: 5% false positive rate. The most widely used threshold in ecommerce CRO.
Required sample size: The baseline from which other levels are measured.
When to use 95%:
- Most A/B tests — CTA text, product images, layout changes, banner copy
- Standard business decisions — this is what most Shopify CRO tools, including CustomFit.ai, default to
- When reporting to stakeholders — 95% is recognized as the standard; it's easier to defend
- Sufficient traffic — if you can reach the required sample in 2-4 weeks, there is no reason to use 90%
Why 95% became the standard: Ronald Fisher somewhat arbitrarily proposed 0.05 as a convenient threshold in 1925. The ecommerce industry adopted it wholesale. It is a reasonable default, not a scientifically optimal choice.
99% Confidence Level: When to Use It
What it means: 1% false positive rate. Very unlikely to ship a false winner.
Required sample size: ~77% larger than at 95% confidence. Tests take significantly longer.
When to use 99%:
- Pricing changes — testing ₹999 vs ₹1,199 for a core SKU; a wrong call costs revenue directly
- Major structural changes — redesigning the checkout flow, changing navigation architecture
- High-traffic core pages — homepage hero, product detail pages for top sellers
- Irreversible or slow-to-reverse changes — technical migrations, checkout platform changes
- Chargebee-style AOV tests — when you're testing subscription pricing and a false positive means locking customers into the wrong plan
Sample Size Impact: A Practical Table
Assume a baseline conversion rate of 3% and you want to detect a 15% relative lift (3% → 3.45%):
| Confidence Level | α | Approx. visitors per variant | Days at 500 visitors/day |
|---|
| 90% | 0.10 | ~3,800 | ~8 days |
| 95% | 0.05 | ~5,200 | ~11 days |
| 99% | 0.01 | ~9,200 | ~19 days |
At lower baseline CVRs (common in India where 1-2% is typical for many categories), these numbers scale up significantly. Use a sample size calculator before starting any test.
The Multiple Testing Problem
Every A/B test at 95% confidence has a 5% false positive rate. If you run 20 tests, you expect 1 false positive even if none of your variants actually help. Run 100 tests and you'll ship ~5 false winners — assuming you ship everything that reaches significance.
This is the multiple comparisons problem. Solutions include:
- Bonferroni correction — divide α by the number of tests. Strict but conservative.
- False Discovery Rate (FDR) control — allows more tests while bounding the proportion of false positives
- Sequential testing / always-valid p-values — used by platforms like Optimizely; adjusts for continuous monitoring
- Hold-out validation — after declaring a winner, run a holdout test to confirm the lift persists
For most D2C brands running 5-15 tests per year, the multiple testing problem is manageable at 95% confidence without formal correction.
Tips and Best Practices
- Set your confidence level before the test, not after — "p-hacking" (looking at results and then adjusting your threshold) destroys statistical validity
- Match confidence to stakes — low-stakes test = 90% is fine; pricing or checkout tests = 99%
- Consider statistical power alongside confidence — a 95% confidence level with 50% power means you'll miss half of real effects. Aim for 80% power minimum (see statistical power)
- Don't extend tests indefinitely — if you've hit your sample size and the result isn't significant, the test is inconclusive. Extending it to "fish for significance" inflates errors
- Segment before concluding — a test that reaches 95% overall may not be significant on mobile; check your key segments before shipping
- Document your thresholds — keep a testing log with pre-specified metrics, sample sizes, and confidence levels so you can audit results later
Key Takeaways
- Confidence level = 1 - false positive rate; 95% means 5% chance of a false positive
- 90% is faster but riskier — use for low-stakes tests or when traffic is very limited
- 95% is the industry standard and the right default for most Shopify A/B tests
- 99% requires ~77% more traffic but is appropriate for high-stakes decisions like pricing or checkout changes
- Confidence level does not tell you the probability the variant is better — that requires Bayesian analysis
- Set your threshold before the test starts and never change it based on interim results
Related reading: Bayesian vs Frequentist A/B Testing | A/B Testing Pillar | Statistical Significance