From the conversion glossary
Concepts referenced in this article, defined.
Concepts referenced in this article, defined.
Run rigorous A/B tests and personalize every visit on Shopify or any storefront — no engineers required.
Bayesian and frequentist A/B testing are two statistical frameworks for deciding whether a variant beats a control. Frequentist testing uses p-values and confidence intervals to reject a null hypothesis at a fixed sample size, while Bayesian testing updates a probability distribution continuously and tells you the chance your variant is better. For most D2C brands running Shopify stores with moderate traffic, understanding which approach your tool uses — and why it matters — directly affects whether you ship winning changes or false positives.
The philosophical split between Bayesian and frequentist statistics is one of the oldest debates in data science, but for ecommerce practitioners it comes down to one practical question: what answer do you want?
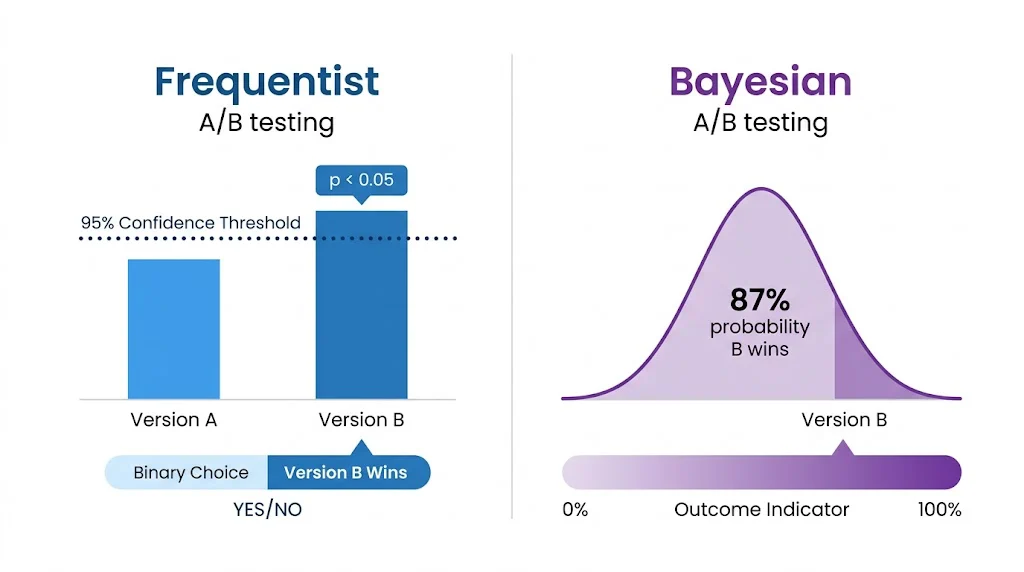
Frequentist A/B testing asks: "If there were no difference between control and variant, how likely is it that we'd see data this extreme?" That probability is the p-value. If p < 0.05, you declare statistical significance and call variant B the winner.
Bayesian A/B testing asks: "Given the data we've collected so far, what is the probability that variant B is actually better than control?" That gives you something more intuitive — a direct probability statement.
Consider a scenario: your Shopify store sells Ayurvedic supplements and you're testing two product page layouts during a Diwali sale window. You have 5 days. A frequentist test might not reach the pre-calculated sample size in time, leaving you with an "inconclusive" result even if variant B looks clearly better. A Bayesian framework would give you a running probability, and if it's at 92% after day 3, you can make an informed call.
Kapiva, a D2C wellness brand, faces this exact trade-off during festive periods when test windows are compressed but decisions still need to be made.
Frequentist A/B testing is the traditional method. Here's the process:
Statistical significance — The threshold below which you reject the null hypothesis. Most ecommerce tests use 95% significance (p < 0.05). See the conversion glossary on statistical significance.
Confidence interval — The range within which the true effect likely falls. A 95% confidence interval does not mean "95% chance the true value is in this range" — it means "if we ran this experiment 100 times, 95% of intervals would contain the true value." This misinterpretation is extremely common.
P-value — Read our conversion glossary entry on p-values for a full explanation. The short version: a p-value of 0.03 does not mean there is a 97% chance variant B is better.
Sample size — Frequentist tests require you to fix your sample size before running. See how to calculate A/B test sample size for the formula.
The biggest practical issue with frequentist testing is peeking. If you check your results daily and stop the test when you see p < 0.05, your actual false positive rate is far higher than 5%. Studies show that peeking at a test 5 times inflates your Type I error rate to ~20%. This means 1 in 5 "winners" you ship may actually be noise.
Most ecommerce teams peek constantly. It's human nature. This is where Bayesian methods have a structural advantage.
Bayesian testing starts with a prior belief about your conversion rates (often a Beta distribution based on historical data), then updates it as new data comes in. The result is a posterior distribution — a full probability distribution over what your conversion rate might be.
From that posterior, you can extract:
Every Bayesian test requires a prior. If you have historical data (e.g., your baseline CVR has been 2.1% ± 0.3% for six months), you can set an informative prior. If you have no idea, you use a flat/uninformative prior (Beta(1,1)), which assumes all conversion rates from 0-100% are equally likely before seeing data.
For new Shopify stores or new product categories, uninformative priors are appropriate. For established stores with months of data, informative priors make your tests more efficient.
| Factor | Frequentist | Bayesian |
|---|---|---|
| Output | p-value, confidence interval | Probability of being best, credible interval |
| Sample size | Fixed upfront | Flexible, can stop when confident |
| Peeking | Inflates error rate | Allowed (with proper thresholds) |
| Interpretability | Counterintuitive (p-value ≠ probability) | Intuitive ("87% chance B wins") |
| Prior knowledge | Not used | Can incorporate historical data |
| Speed | Slower (needs fixed N) | Can be faster with stopping rules |
| Tool availability | Widely available | Less common, often requires configuration |
| False positive risk | Fixed at α (if protocol followed) | Depends on threshold chosen |
Choose frequentist when:
Choose Bayesian when:
For most Indian D2C brands on Shopify, here is a pragmatic approach:
Small stores (< 10,000 monthly visitors): Use Bayesian with a PBB threshold of 90-95% and track expected loss. Accept that tests will take longer or carry more uncertainty. Focus on big changes (30%+ expected lift) where even noisy data gives signal.
Medium stores (10,000 – 100,000 monthly visitors): Use frequentist at 95% significance with pre-calculated sample sizes. Tools like CustomFit.ai make this calculation automatic. Resist peeking.
Large stores (> 100,000 monthly visitors): Either approach works. Consider Bayesian for rapid iteration cycles and frequentist for major structural changes where false positives are costly.
Related reading: A/B Testing Confidence Level: 90% vs 95% vs 99% | How to Calculate Sample Size | Statistical Significance Explained